Like every reasonable project, the starting point consists
in reading a lot of papers in order to increase the “know how” of the group and
realize the solutions that are already present in literature. In our specific
case we had the opportunity to see that there are two main families of
solutions: digital and analogical, respectively. In both cases the aim is to generate
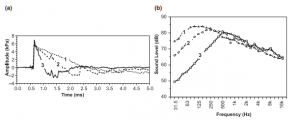
a wave that must delete the noise (like in the figure) obtaining a null noise
in the area near the ears.
To understand analogic
methodologies, we suggest to read carefully the sections [21], [22] and [23]
listed in the bibliography. From those papers we understand that even if
analogic world is cheaper, it’s not an accurate solution. This is mainly
because the circuitry must have minimum errors on gain and phase in order to
guarantee the stability of the system. Moreover, this solution is not robust if
we change the environment or the temperature that surrounds us. Another problem
is that we need to know exactly the transfer function of the system that is due
to the ear’s auricle of the user.
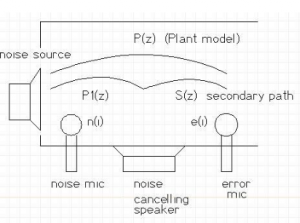
Among all the famous algorithms that are employed in Active
Noise Reduction (ANR) we find FXLMS and FXLMM (see [26] in bibliography). In
particular, this last one is the most efficient and stable one for impulsive
noise.
Active filters for noise reduction are much more efficient
to reduce noise at high frequency, while instead for low frequencies it’s
better to choose properly the transmission medium crossed by the noise before
getting to the hearing channel.
To look deeper inside the ANR theory, look at the papers in
[26],[36] and [37].



{kind=link}
{kind=link}
{kind=link}